CLOVA Speech Recognition(CSR) 개요
api.ncloud-docs.com
자세한 API 사용법은 위의 링크에서 확인할 수 있습니다.
STT(Speech To Text)란?
사용자로부터 음성 데이터를 입력 받고, 그에 맞는 인식 결과를 텍스트로 반환하는 것을 일컫는다.
CSR(Clova Speech Recognition)이란?
사람의 목소리를 인식하여 작동하는 비서 애플리케이션, 챗봇, 음성 메모 등의 서비스를 만들 때
활용할 수 있는 음성인식 API 서비스입니다.
음성 데이터는 API를 통해 CLOVA Speech Recognition(CSR) 엔진으로 전송되며,
해당 음성 데이터를 인식해서 텍스트로 변환하여 전달해줍니다.
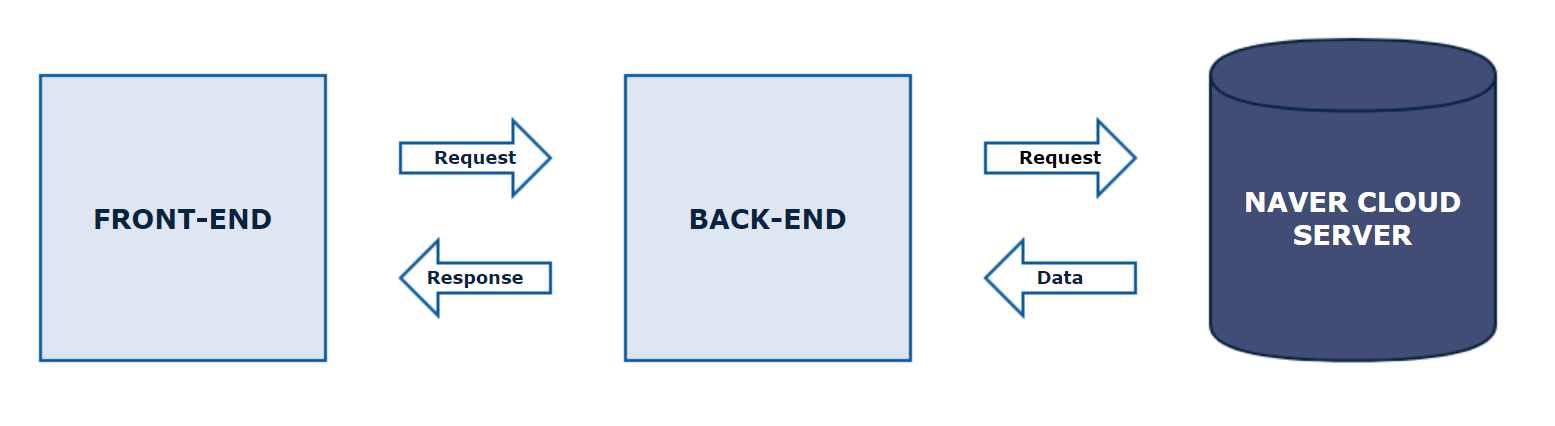
| GOAL |
| 1. 네이버 클라우드 플랫폼 콘솔에서 애플리케이션 등록 후, 클라이언트 아이디를 발급받는다. |
| 2. 음성인식할 음성 데이터를 HTTP 통신으로 음성인식 서버에 전달한다. |
| 3. React의 react-media-recorder 모듈에 대해 이해한다. |
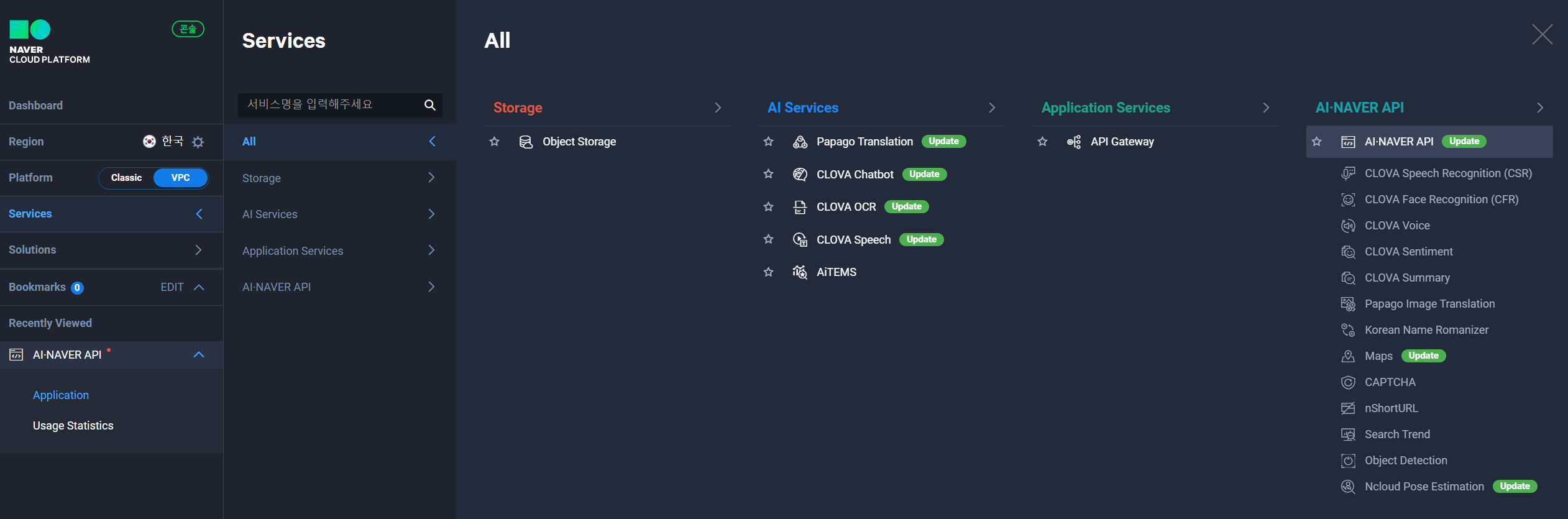
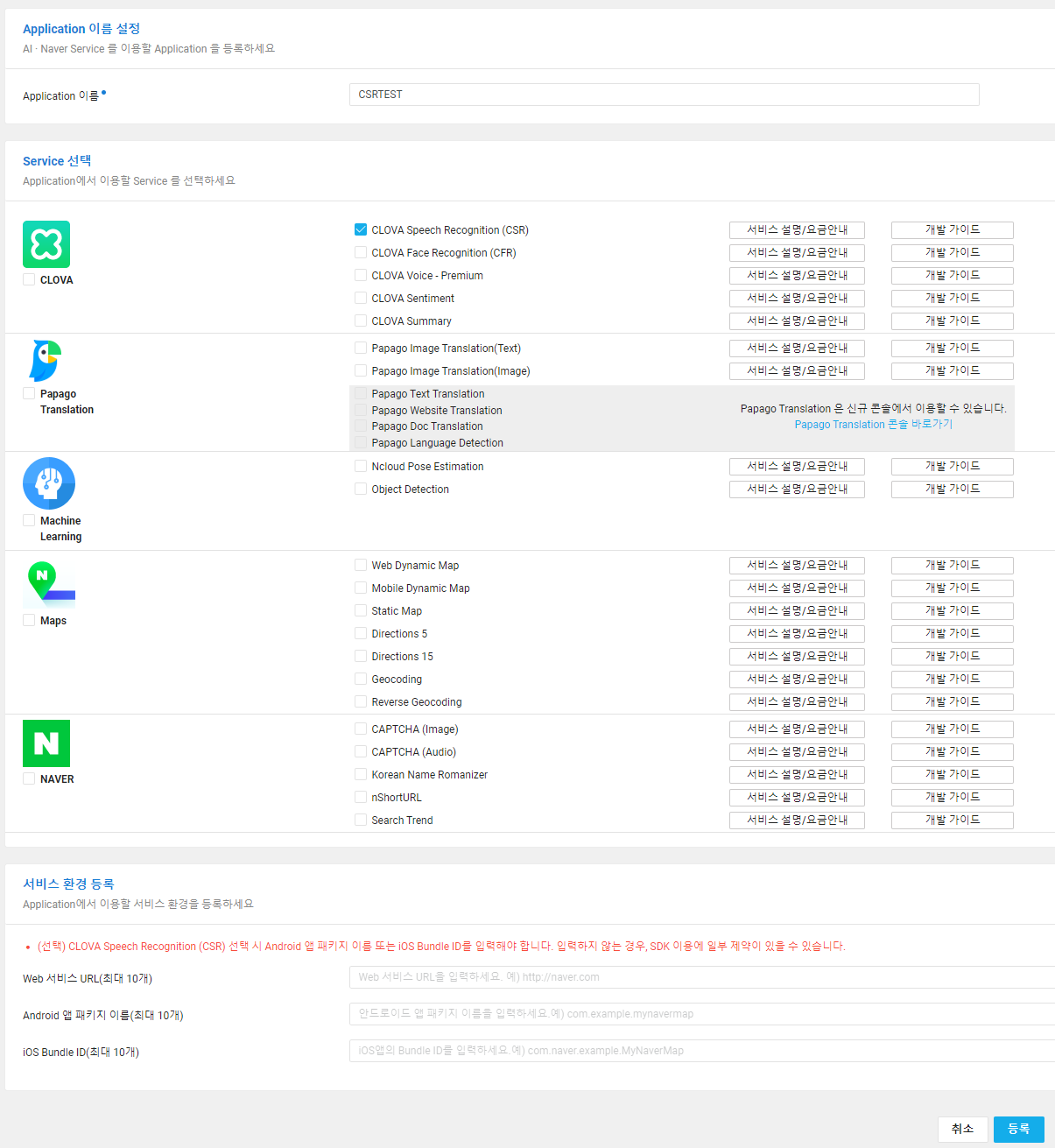
1. Application을 등록하고 Client ID, Secret 발급받기


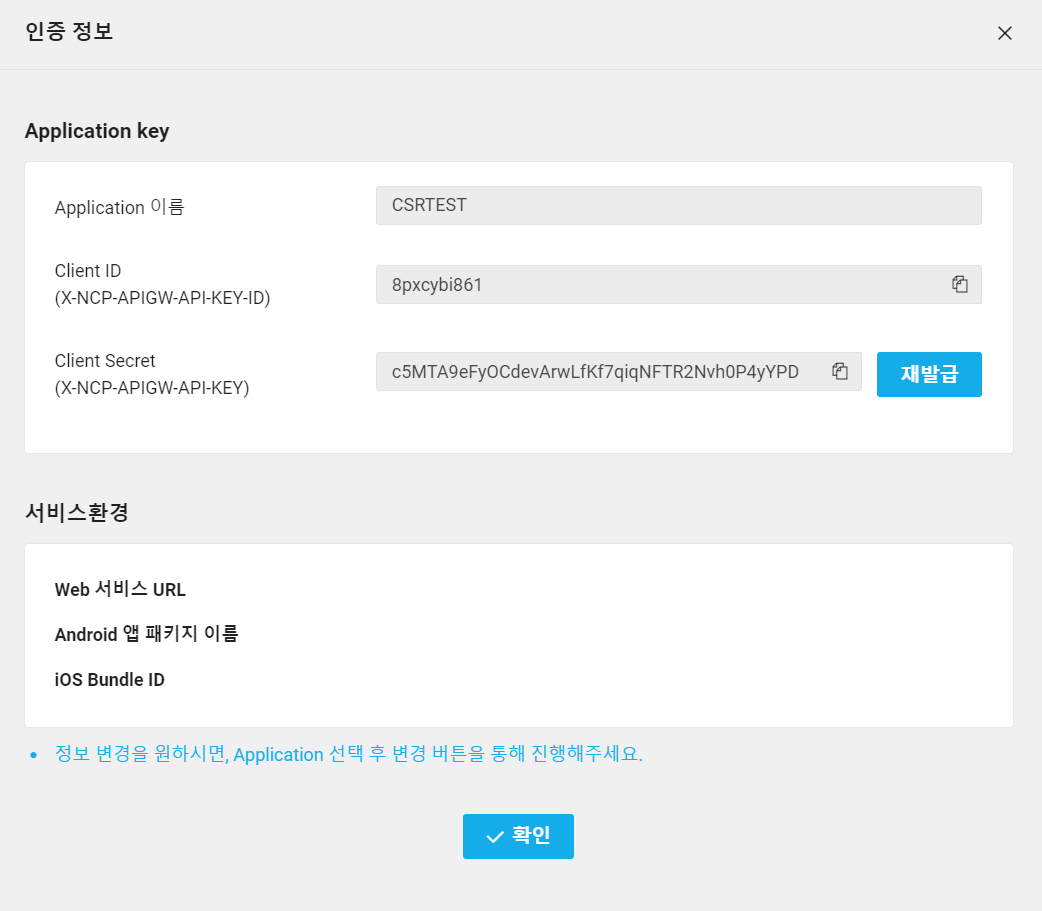
2. 음성인식할 음성 데이터를 HTTP 통신으로 음성인식 서버에 전달
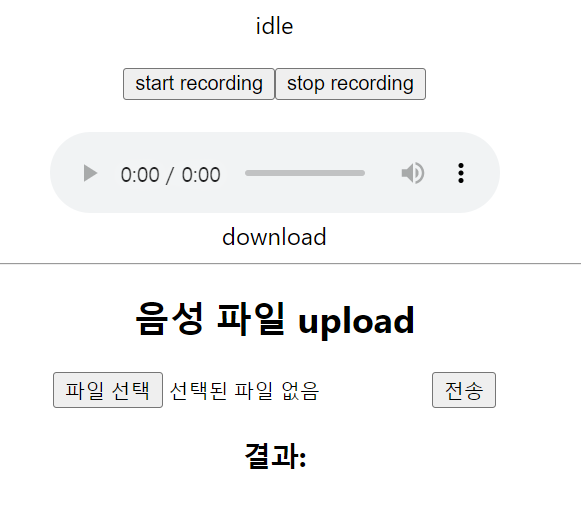
화면단에 대해 간략하게 설명하자면, start recording 버튼을 클릭하면 녹음을 시작할 수 있고
stop recording 버튼을 클릭하면 녹음을 끝낼 수 있다.
후에, download 버튼을 클릭하면 녹음한 파일을 wav 형식의 파일로 다운 받을 수 있고
음성 파일 upload 단에서 파일을 업로드 후에 서버로 전송하면 결과에 해당 음성에 대한 텍스트 결과가 출력된다.
@RestController
public class NaverCloudController {
@PostMapping("fileUpload")
public String fileUpload(@RequestParam("uploadFile") MultipartFile uploadFile, HttpServletRequest req) {
System.out.println("NaverCloudController STT : " + new Date());
String uploadPath = req.getServletContext().getRealPath("/upload");
String fileName = uploadFile.getOriginalFilename();
String filePath = uploadPath + "/" + fileName;
try {
BufferedOutputStream os = new BufferedOutputStream(new FileOutputStream(new File(filePath)));
os.write(uploadFile.getBytes());
os.close();
} catch (Exception e) {
e.printStackTrace();
return "fail";
}
String resp = NaverCloud.stt(filePath);
return resp;
}
}
서버단에는 위와 같이 클라이언트에서 업로드한 파일에 대해서 처리하고,
filePath를 Parameter값으로 하는 NaverCloud Class의 stt라는 메소드를 실행하여
문자열을 반환하는 fileUpload 라는 메소드가 있다.
public class NaverCloud {
public static String stt(String filePath) {
String clientId = "취득한 clientId"; // Application Client ID";
String clientSecret = "취득한 clientSecret"; // Application Client Secret";
StringBuffer response = null;
try {
String imgFile = filePath;
File voiceFile = new File(imgFile);
String language = "Kor"; // 언어 코드 ( Kor, Jpn, Eng, Chn )
String apiURL = "https://naveropenapi.apigw.ntruss.com/recog/v1/stt?lang=" + language;
URL url = new URL(apiURL);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setUseCaches(false);
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestProperty("Content-Type", "application/octet-stream");
conn.setRequestProperty("X-NCP-APIGW-API-KEY-ID", clientId);
conn.setRequestProperty("X-NCP-APIGW-API-KEY", clientSecret);
OutputStream outputStream = conn.getOutputStream();
FileInputStream inputStream = new FileInputStream(voiceFile);
byte[] buffer = new byte[4096];
int bytesRead = -1;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
outputStream.flush();
inputStream.close();
BufferedReader br = null;
int responseCode = conn.getResponseCode();
if(responseCode == 200) { // 정상 호출
br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
} else { // 오류 발생
System.out.println("error!!!!!!! responseCode= " + responseCode);
br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
}
String inputLine;
if(br != null) {
response = new StringBuffer();
while ((inputLine = br.readLine()) != null) {
response.append(inputLine);
}
br.close();
System.out.println(response.toString());
} else {
System.out.println("error !!!");
}
} catch (Exception e) {
System.out.println(e);
}
return response.toString();
}
}
stt 메소드는 어느 클래스에서나 객체 생성 없이 사용할 수 있도록 static으로 작성했다.
AIㆍAPI에서 처리한 결과는 StringBuffer타입의 response라는 변수에 담기므로 전역변수로 설정하고,
해당 변수에 toString 메소드로 얻은 String 값을 반환하는 메소드이다.
import React, {useState} from 'react';
import axios from 'axios';
import { ReactMediaRecorder } from 'react-media-recorder';
function App() {
const [resp, setResp] = useState('');
const fileUpload = async (e) =>{
e.preventDefault();
let formData = new FormData();
formData.append("uploadFile", document.frm.uploadFile.files[0]);
axios.post("http://localhost:3000/fileUpload", formData)
.then(function(res){
alert('success');
setResp(res.data.text);
})
.catch(function(error){
alert(error);
})
}
return (
<div align="center">
<ReactMediaRecorder
audio
render={({status, startRecording, stopRecording, mediaBlobUrl }) => (
<div>
<p>{status}</p>
<button onClick={startRecording}>start recording</button>
<button onClick={stopRecording}>stop recording</button><br /><br />
<audio src={mediaBlobUrl} controls></audio><br />
<a href={mediaBlobUrl} download="mySound.wav">download</a>
</div>
)}
/>
<hr/>
<h2>음성 파일 upload</h2>
<form name="frm" onSubmit={fileUpload} encType="multipart/form-data">
<input type="file" name="uploadFile" accept='*'/>
<input type="submit" value="전송" />
</form>
<h3>결과:{resp}</h3>
</div>
);
}
export default App;
프론트 단에는 위와 같이 코드를 작성하였다.
비동기방식으로 서버에 음성 파일을 전달하고, 음성 파일에 대한 텍스트값을 전달 받는 코드이다.
React는 클라이언트에서 녹음을 하고 해당 파일을 다운로드 받을 수 있도록
React-Media-Recorder라는 모듈을 제공한다.
npm install react-media-recorder
VSCode의 터미널에서 위와 같이 명령어를 입력하여 모듈을 설치하면 된다.
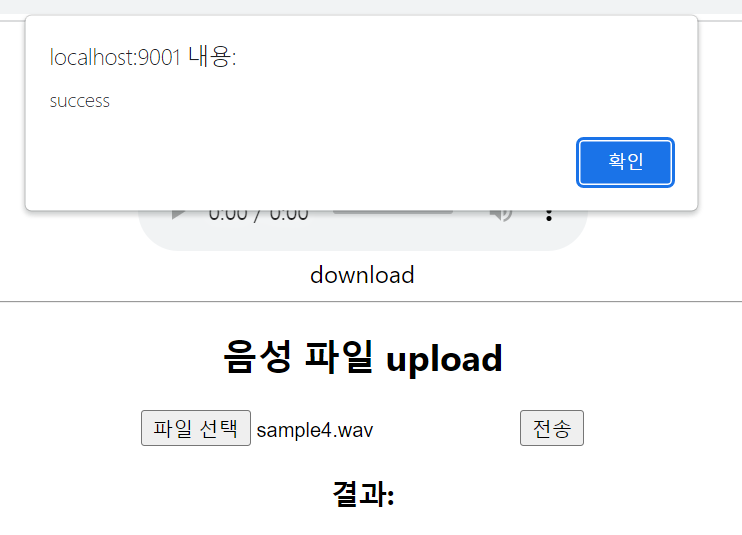
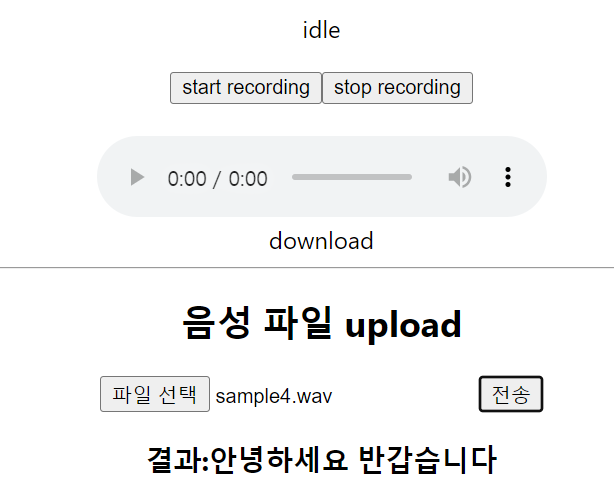
필자는 "안녕하세요 반갑습니다" 라는 문장을 구사한 음성파일을 서버에 전송해보았다.
success라는 Alert이 출력되고, 결과값에 해당 음성파일에 대한 텍스트가 잘 출력되는 것을 확인할 수 있다.
마치며
매번 웹개발만 하다가 이런 AIㆍAPI를 이용해보니 재미가 있었다.
파이널 프로젝트에서 잘 사용하면 좋은 퀄리티의 작품을 만들 수 있을것 같다.
'네이버 클라우드' 카테고리의 다른 글
| [네이버 클라우드] CLOVA Voice API, TTS(Text To Speech) (0) | 2023.04.02 |
|---|---|
| [네이버 클라우드] CFR(CLOVA Face Recognition) (1) | 2023.03.31 |


댓글