본문 내용은 모두 필자가 공부하며 직접 정리한 내용입니다.
Kdata 데이터자격검정의 SQL 개발자(SQLD) 가이드를 참고하였습니다.
─지난 글 보기─
[SQLD 도전기] 데이터 모델과 성능(4) - 대량 데이터에 따른 성능
본문 내용은 모두 필자가 공부하며 직접 정리한 내용입니다. Kdata 데이터자격검정의 SQL 개발자(SQLD) 가이드를 참고하였습니다. ─지난 글 보기─ [SQLD 도전기] 데이터 모델과 성능(3) - 반정규화와
itsmesunky.tistory.com
과목 1 데이터 모델링의 이해
제 2장 데이터 모델과 성능
제 5절 데이터베이스 구조와 성능
1. 슈퍼타입/서브타입 모델의 성능고려 방법
가. 슈퍼/서브타입 데이터 모델의 개요
ㆍExtended ER모델이라고 부르는 이른바 슈퍼/서브타입 데이터 모델은 최근에 데이터 모델링을 할 때 자주 쓰이는 모델링 방법
ㆍ이 모델이 자주 쓰이는 이유는 업무를 구성하는 데이터의 특징을 공통과 차이점의 특징을 고려하여 효과적으로 표현할 수 있기 때문
ㆍ공통의 부분을 슈퍼타입으로 모델링하고 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성에 대해서는
별도의 서브엔터티로 구분하여 업무의 모습을 정확하게 표현
ㆍ물리적인 데이터 모델로 변환을 할 때 선택의 폭을 넓힐 수 있는 장점
ㆍ논리적인 데이터 모델에서 이용되는 형태, 분석단계에서 많이 쓰이는 모델
ㆍ물리적인 데이터 모델을 설계하는 단계에서는 슈퍼/서브타입 데이터 모델을 일정한 기준에 의해 변환
(*기준 : 데이터의 양, 해당 테이블에 발생되는 트랜잭션의 유형)

나. 슈퍼/서브타입 데이터 모델의 변환

ㆍ슈퍼/서브타입에 대한 변환을 잘못하면 성능이 저하되는 이유는
트랜잭션 특성을 고려하지 않고 테이블이 설계되었기 때문이다.
1) 트랜잭션은 항상 전체를 대상으로 일괄로 처리 → 전체를 하나의 테이블로 구성(Rollup)

2) 트랜잭션은 항상 서브타입 개별로 처리 → 서브타입을 개별 테이블로 구성(Rolldown)
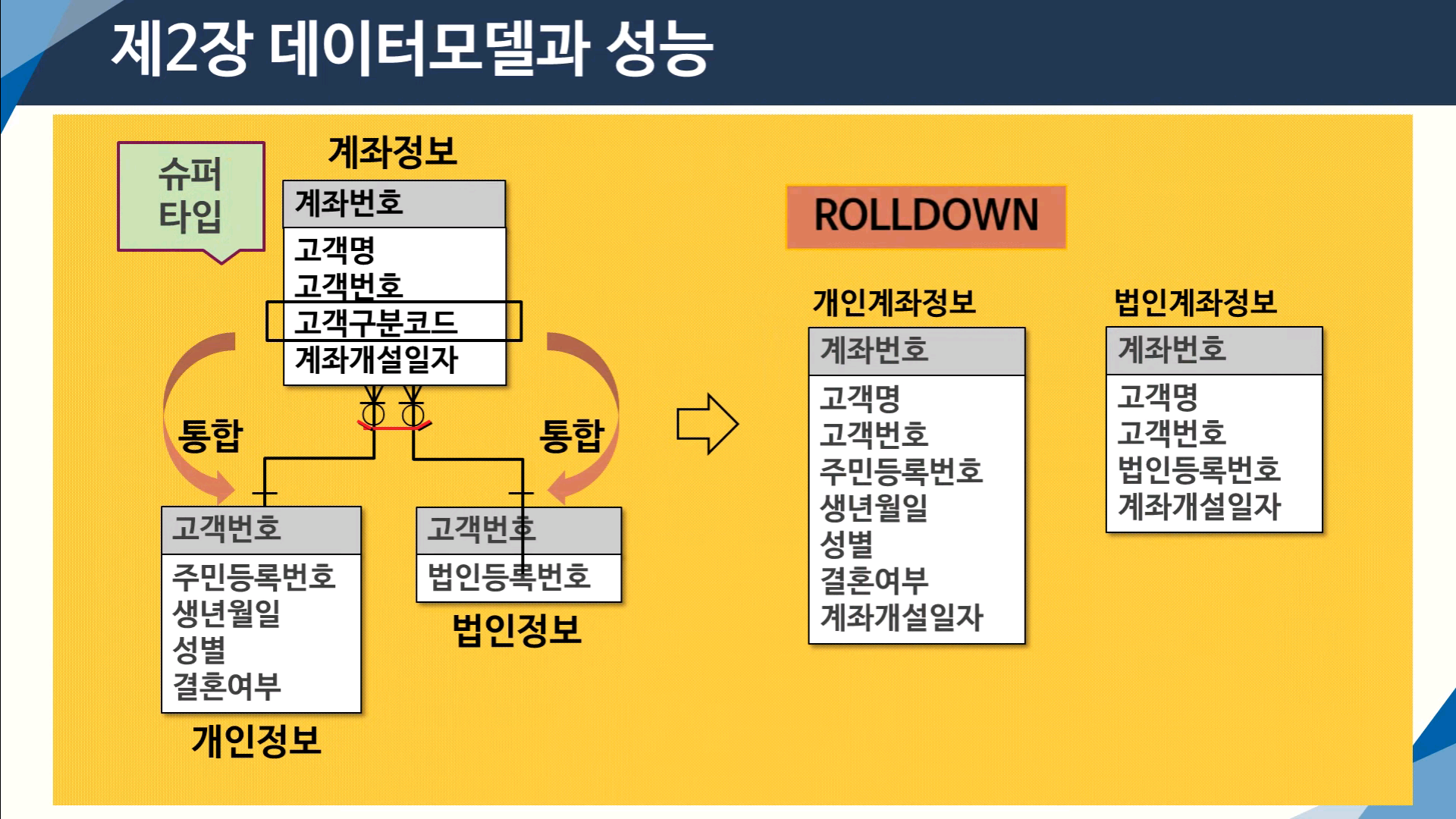
3) 트랜잭션은 항상 슈퍼+서브 타입을 공동으로 처리 → 슈퍼타입+서브타입 테이블로 구성(Identity)

다음에는 분산 데이터베이스와 성능에 관한 내용을 정리하여 포스팅하겠습니다.
'데이터베이스 > SQLD' 카테고리의 다른 글
| [SQLD 도전기] SQL 기본(1) - 관계형 데이터베이스 개요 (0) | 2022.10.12 |
|---|---|
| [SQLD 도전기] 데이터 모델과 성능(6) - 분산 데이터베이스와 성능 (0) | 2022.10.11 |
| [SQLD 도전기] 데이터 모델과 성능(4) - 대량 데이터에 따른 성능 (0) | 2022.10.11 |
| [SQLD 도전기] 데이터 모델과 성능(3) - 반정규화와 성능 (0) | 2022.10.11 |
| [SQLD 도전기] 데이터 모델과 성능(2) - 정규화와 성능 (0) | 2022.10.10 |




댓글